Jim Chow, Ben Pfaff, Tal Garfinkel, Kevin Christopher, Mendel Rosenblum
{jchow,blp,talg,kchristo,mendel}@cs.stanford.edu
Stanford University Department of Computer Science
We describe a system we have developed for analyzing sensitive data lifetime through whole system simulation called TaintBochs. TaintBochs tracks sensitive data by ``tainting'' it at the hardware level. Tainting information is then propagated across operating system, language, and application boundaries, permitting analysis of sensitive data handling at a whole system level.
We have used TaintBochs to analyze sensitive data handling in several large, real world applications. Among these were Mozilla, Apache, and Perl, which are used to process millions of passwords, credit card numbers, etc. on a daily basis. Our investigation reveals that these applications and the components they rely upon take virtually no measures to limit the lifetime of sensitive data they handle, leaving passwords and other sensitive data scattered throughout user and kernel memory. We show how a few simple and practical changes can greatly reduce sensitive data lifetime in these applications.
As data lifetime increases so does the likelihood of exposure to an attacker. Exposure can occur by way of an attacker gaining access to system memory or to persistent storage (e.g. swap space) to which data has leaked. Careless data handling also increases the risk of data exposure via interaction with features such as logging, command histories, session management, crash dumps or crash reporting [6], interactive error reporting, etc.
Unfortunately, even simple questions about data lifetime can be surprisingly difficult to answer in real systems. The same data is often handled by many different components, including device drivers, operating system, system libraries, programming language runtimes, applications, etc., in the course of a single transaction. This limits the applicability of traditional static and dynamic program analysis techniques, as they are typically limited in scope to a single program, often require program source code, and generally cannot deal with more than one implementation language.
To overcome these limitations we have developed a tool based on whole-system simulation called TaintBochs, which allows us to track the propagation of sensitive data at hardware level, enabling us to examine all places that sensitive data can reside. We examine systems with TaintBochs by running the entire software stack, including operating system, application code, etc. inside a simulated environment. Every byte of system memory, device state, and relevant processor state is tagged with a taint-status flag. Data is ``tainted'' if it is considered sensitive.
TaintBochs propagates taint flags whenever their corresponding values in hardware are involved in an operation. Thus, tainted data is tracked throughout the system as it flows through kernel device drivers, user-level GUI widgets, application buffers, etc. Tainting is introduced when sensitive data enters the system, such as when a password is read from the keyboard device, an application reads a particular data set, etc.
We applied TaintBochs to analyzing the lifetime of password information in a variety of large, real-world applications, including Mozilla, Apache, Perl, and Emacs on the Linux platform. Our analysis revealed that these applications, the kernel, and the libraries that they relied upon generally took no steps to reduce data lifetime. Buffers containing sensitive data were deallocated without being cleared of their contents, leaving sensitive data to sit on the heap indefinitely. Sensitive data was left in cleartext in memory for indeterminate periods without good reason, and unnecessary replication caused excessive copies of password material to be scattered all over the heap. In the case of Emacs our analysis also uncovered an interaction between the keyboard history mechanism and shell mode which caused passwords to be placed into the keyboard history in the clear.
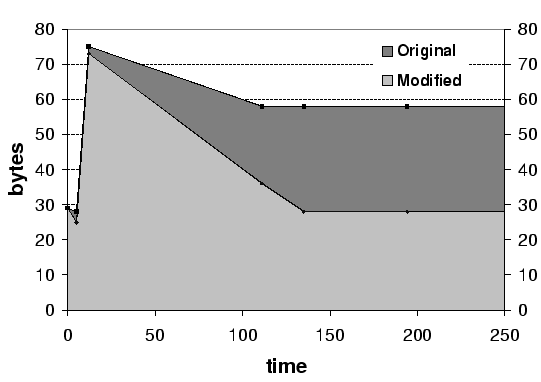
On a positive note our analysis revealed that simple modifications could yield significant improvements. For example, adding a small amount of additional code to clear buffers in the string class destructor in Mozilla greatly reduced the amount of sensitive input form data (e.g. CGI password data) in the heap without a noticeable impact on either code complexity or performance.
Our exposition proceeds as follows. In section 2 we present the motivation for our work, discussing why data lifetime is important to security, why minimizing data lifetime is challenging, and how whole system simulation can help. Section 3 describes the design of TaintBochs, its policy for propagating taint information and the rationale behind it, its support for introducing and logging taints, and our analysis framework. Section 4 describes our experiments on Mozilla, Apache, Perl, and Emacs, analyzes the results, and describes a few simple changes we made to greatly reduced the quantity of long-lived tainted data in programs we examined. Section 5 covers related work. Section 6 describes our thoughts about future work in this area. Finally, section 7 concludes.
The longer sensitive data resides in memory, the greater the risk of exposure. A long running process can easily accumulate a great deal of sensitive data in its heap simply by failing to take appropriate steps to clear that memory before free()ing it. A skillful attacker observing such a weakness could easily recover this information from a compromised system simply by combing an application's heap. More importantly, the longer data remains in memory the greater its chances of being leaked to disk by swapping, hibernation, a virtual machine being suspended, a core dump, etc.
Basic measures for limiting the lifetime of sensitive data including password and key material and keeping it off persistent storage have become a standard part of secure software engineering texts [29] and related literature [13,28]. Extensive work has been done to gauge the difficulty of purging data from magnetic media once it has been leaked there [11], and even issues of persistence in solid state storage have been examined [12]. Concern about sensitive data being leaked to disk has fueled work on encrypted swap [21] and encrypted file systems [4] which can greatly reduce the impact of sensitive data leaks to disk. Unfortunately, these measures have seen fairly limited deployment.
Identifying long-lived data is not so obviously useful as, say, detecting remotely exploitable buffer overflows. It is a more subtle issue of ensuring that principles of conservative design have been followed to minimize the impact of a compromise and decrease the risk of harmful feature interactions. The principles that underly our motivation are: first, minimize available privilege (i.e. sensitive data access) throughout the lifetime of a program; second, defense in depth, e.g. avoid relying solely on measures such as encrypted swap to keep sensitive data off disk.
While awareness of data lifetime issues runs high among the designers and implementers of cryptographic software, awareness is low outside of this community. This should be a significant point for concern. As our work with Mozilla in particular demonstrates, even programs that should know better are entirely careless with sensitive data. Perhaps one explanation for this phenomenon is that if data is not explicitly identified as, for example, a cryptographic key, it receives no special handling. Given that most software has been designed this way, and that this software is being used for a wide range of sensitive applications, it is important to have an easy means of identifying which data is sensitive, and in need of special handling.
The many factors which affect data lifetime make building secure systems a daunting task. Even systems which strive to handle data carefully are often foiled by a variety of factors including programmer error and weaknesses in components they rely upon. This difficulty underscores the need for tools to aid examining systems for errors.
Common measures taken to protect sensitive data include zeroing out memory containing key material as soon as that data is no longer needed (e.g. through the C memset() function) and storing sensitive material on pages which have been pinned in memory (e.g. via the UNIX mmap() or mlock() system calls), to keep them off of persistent storage. These measures can and have failed in a variety of ways, from poor interactions between system components with differing assumptions about data lifetime to simple programmer error.
A very recent example is provided by Howard [14] who noted that memset() alone is ineffective for clearing out memory with any level of optimization turned on in Borland, Microsoft, and GNU compilers. The problem is that buffers which are being memset() to clear their contents are effectively ``dead'' already, i.e. they will never be read again, thus the compiler marks this code as redundant and removes it. When this problem was revealed it was found that a great deal of software, including a variety of cryptographic libraries written by experienced programmers, had failed to take adequate measures to address this. Now that this problem has been identified, multiple ad-hoc ways to work around this problem have been developed; however, none of them is entirely straightforward or foolproof.
Sometimes explicitly clearing memory is not even possible. If a program unexpectedly halts without clearing out sensitive data, operating systems make no guarantees about when memory will be cleared, other than it will happen before the memory is allocated again. Thus, sensitive data can live in memory for a great deal of time before it is purged. Similarly, socket buffers, IPC buffers, and keyboard input buffers, are all outside of programmer control.
Memory locking can fail for a wide range of reasons. Some are as simple as memory locking functions that provide misleading functionality. For example, a pair of poorly documented memory locking functions in some versions of Windows, named VirtualLock() and VirtualUnlock(), are simply advisory, but this has been a point of notable confusion [13].
OS hibernation features do not respect memory locking guarantees. If programs have anticipated the need, they can usually request notification before the system hibernates; however, most programs do not.
Virtual machine monitors such as VMware Workstation and ESX [30] have limited knowledge of the memory management policies of their guest OSes. Many VMM features, including virtual memory (i.e. paging), suspending to disk, migration, etc., can write any and all state of a guest operating system to persistent storage in a manner completely transparent to the guest OS and its applications. This undermines any efforts by the guest to keep memory off of storage such as locking pages in memory or encrypting the swap file.
In addition to these system level complications, unexpected interactions between features within or across applications can expose sensitive data. Features such as logging, command histories, session management, crash dumps/crash reporting, interactive error reporting, etc. can easily expose sensitive data to compromise.
Systems are made of many components that application designers did not develop and whose internals they have little a priori knowledge of. Further, poor handling of sensitive data is pervasive. While a few specialized security applications and libraries are quite conservative about their data handling, most applications, language runtimes, libraries and operating system are not. As we discuss later in Section 4, even the most common components such as Mozilla, Apache, Perl, and Emacs and even the Linux kernel are relatively profligate with their handling of sensitive data. This makes building systems which are conservative about sensitive data handling extremely difficult.
TaintBoch's approach of tracking sensitive data of interest via whole system simulation is an attractive platform for tackling this problem. It is practical, relatively simple to implement (given a simulator), and possesses several unique properties that make it particularly well suited to examining data lifetime.
TaintBochs's whole system view allows interactions between components to be analyzed, and the location of sensitive data to be easily identified. Short of this approach, this is a surprisingly difficult problem to solve. Simply greping for a sensitive string to see if it is present in system memory will yield limited useful information. In the course of traversing different programs, data will be transformed through a variety of encodings and application specific data formats that make naive identification largely impossible. For example, in section 4 we find that a password passing from keyboard to screen is alternately represented as keyboard scan codes, plain ASCII, and X11 scan codes. It is buffered as a set of single-character strings, and elements in a variety of circular queues.
Because TaintBochs tracks data at an architectural level, it does not require source code for the components that an analysis traverses (although this does aid interpretation). Because analysis is done at an architectural level, it makes no assumptions about the correctness of implementations of higher level semantics. Thus, high level bugs or misfeatures (such as a compiler optimizing away memset()) are not overlooked.
Comparison of a whole system simulation approach with other techniques is discussed further in the related work, section 5.
TaintBochs is our tool for measuring data lifetime. At its heart is a hardware simulator that runs the entire software stack being analyzed. This software stack is referred to as the guest system. TaintBochs is based on the open-source IA-32 simulator Bochs v2.0.2 [5]. Bochs itself is a full featured hardware emulator that can emulate a variety of different CPUs (386, 486, or Pentium) and I/O devices (IDE disks, Ethernet card, video card, sound card, etc.) and can run unmodified x86 operating systems including Linux and Windows.
Bochs is a simulator, meaning that guest code never runs directly on the underlying processor--it is merely interpreted, turning guest hardware instructions into appropriate actions in the simulation software. This permits incredible control, allowing us to augment the architecture with taint propagation, extend the instruction set, etc.
We have augmented Bochs with three capabilities to produce TaintBochs. First, we provide the ability to track the propagation of sensitive data through the system at a hardware level, i.e. tainting. Second, we have added logging capabilities that allow system state such as memory and registers at any given time during a system's execution history to be examined. Finally, we developed an analysis framework that allows information about OS internals, debug information for the software that is running, etc. to be utilized in an integrated fashion to allow easy interpretation of tainting information. This allows us to trace tainted data to an exact program variable in an application (or the kernel) in the guest, and code propagating tainting to an exact source file and line number.
Our basic usage model consists of two phases. First, we run a simulation in which sensitive data (e.g. coming from the keyboard, network, etc.) is identified as tainted. The workload consists of normal user interaction, e.g. logging into a website via a browser. In the second phase, the simulation data is analyzed with the analysis framework. This allows us to answer open-ended queries about the simulation, such as where tainted data came from, where it was stored, how it was propagated, etc.
We will begin by looking at the implementation of TaintBochs, focusing on modifications to the simulator to facilitate tainting, logging, etc. We will then move on to examine the analysis framework and how it can be used with other tools to gain a complete picture of data lifetime in a system.
There are two central issues to implementing hardware level tainting: first, tracking the location of sensitive state in the system, and, second, deciding how to evolve that state over time to keep a consistent picture of which state is sensitive. We will examine each of these issues in turn.
To track the location of sensitive data in TaintBochs, we added another memory, set of registers, etc. called a shadow memory. The shadow memory tracks taint status of every byte in the system. Every operation performed on machine state by the processor or devices causes a parallel operation to be performed in shadow memory, e.g. copying a word from register A to location B causes the state in the shadow register A to be copied to shadow location B. Thus to determine if a byte is tainted we need only look in the corresponding location in shadow memory.
If any bit in a byte is tainted, the entire byte is considered tainted. Maintaining taint status at a byte granularity is a conservative approximation, i.e. we do not ever lose track of sensitive data, although some data may be unnecessarily tainted. Bit granularity would take minimal additional effort, but we have not yet encountered a situation where this would noticeably aid our analysis.
For simplicity, TaintBochs only maintains shadow memory for the guest's main memory and the IA-32's eight general-purpose registers. Debug registers, control registers, SIMD (e.g. MMX, SSE) registers, and flags are disregarded, as is chip set and I/O device state. Adding the necessary tracking for other processor or I/O device state (e.g. disk, frame buffer) would be quite straightforward, but the current implementation is sufficient for many kinds of useful analysis. We are not terribly concerned about the guest's ability to launder taint bits through the processor's debug registers, for example, as our assumption is that software under analysis is not intentionally malicious.
We must decide how operations in the system should affect shadow state. If two registers A and B are added, and one of them is tainted, is the register where the result are stored also tainted? We refer to the collective set of policies that decide this as the propagation policy.
In the trivial case where data is simply copied, we perform the same
operation in the address space of shadow memory. So, if the assignment
![]() executes on normal memory, then
executes on normal memory, then
![]() is also executed on shadow memory. Consequently, if
is also executed on shadow memory. Consequently, if ![]() was
tainted then
was
tainted then ![]() is now also tainted, and if
is now also tainted, and if ![]() was not tainted,
was not tainted, ![]() is now
also no longer tainted.
is now
also no longer tainted.
The answer is less straightforward when an instruction produces a new value based on a set of inputs. In such cases, our simulator must decide on whether and how to taint the instruction's output(s). Our choices must balance the desire to preserve any possibly interesting taints against the need to minimize spurious reports, i.e. avoid tainting too much data or uninteresting data. This roughly corresponds to the false negatives vs. false positives trade-offs made in other taint analysis tools. As we will see, it is in general impossible to achieve the latter goal perfectly, so some compromises must be made.
Processor instructions typically produce outputs that are some function of their inputs. Our basic propagation policy is simply that if any byte of any input value is tainted, then all bytes of the output are tainted. This policy is clearly conservative and errs on the side of tainting too much. Interestingly though, with the exception of cases noted below, we have not yet encountered any obviously spurious output resulting from our policy.
This situation arises routinely. For example, Linux routinely remaps keyboard device data through a lookup table before sending keystrokes to user programs. Thus, user programs never directly see the data read in from the keyboard device, only the non-tainted values they index in the kernel's key remapping table.
Clearly this is not what we want, so we augmented our propagation policy to handle tainted indexes (i.e. tainted pointers) with the following rule: if any byte of any input value that is involved in the address computation of a source memory operand is tainted, then the output is tainted, regardless of the taint status of the memory operand that is referenced.
For our purposes, the output of constant functions never pose a security risk, even with tainted inputs, since the input values are not derivable from the output. In the xor example above, it is no less the situation as if the programmer had instead written mov eax, 0. In the xor case, our naive propagation policy taints the output, and in the mov case, our propagation policy does not taint the output (since immediate inputs are never considered tainted).
Clearly, our desire is to never taint the output of constant functions. And while this can clearly be done for special cases like xor eax, eax or similar sequences like sub eax, eax, this cannot be done in general since the general case (of which the xor and sub examples are merely degenerate members) is an arbitrary sequence of instructions that ultimately compute a constant function. For example, assuming eax is initially tainted, the sequence:
mov ebx, eax ; ebx = eax add ebx, ebx ; ebx = 2 * eax shl eax, 1 ; eax = 2 * eax xor ebx, eax ; ebx = 0
Always computes (albeit circuitously) zero for ebx, regardless of the original value of eax. By the time the instruction simulation reaches the xor, it has no knowledge of whether its operands have the same value because of some deterministic computation or through simple chance; it must decide, therefore, to taint its output.
One might imagine a variety of schemes to address this problem. Our approach takes advantage of the semantics of tainted values. For our research, we are interested in tainted data representing secrets like a user-typed password. Therefore, we simply define by fiat that we are only interested in taints on non-zero values. As a result, any operation that produces a zero output value never taints its output, since zero outputs are, by definition, uninteresting.
This simple heuristic has the consequence that constant functions producing nonzero values can still be tainted. This has not been a problem in practice since constant functions themselves are fairly rare, except for the degenerate ones that clear out a register. Moreover, tainted inputs find their way into a constant function even more rarely, because tainted memory generally represents a fairly small fraction of the guest's overall memory.
A concrete example of this situation occurs in Linux, where keyboard input is used as a source of entropy for the kernel's random pool. Data collected into the random pool is passed through various mixing functions, which include cryptographic hashes like SHA-1. Although derivatives of the original keyboard input are used by the kernel when it extracts entropy from the pool, no practical information can be gleaned about the original keyboard input from looking at the random number outputs (at least, not easily).
Our system does not currently try to remove tainted outputs resulting from one-way functions, since instances of such taints are few and easily identifiable. Moreover, such taints are often useful for identifying the spread of tainted data, for example, the hash of a password is often used as a cryptographic key.
if (x == 0) y = 0; else if (x == 1) y = 1; ... else if (x == 255) y = 255;
effectively copies x to y, but since TaintBochs does not taint comparison flags or the output of instructions that follow a control flow decision based on them, the associated taint for x does not propagate to y. Interestingly, the Windows 2000 kernel illustrates this problem when translating keyboard scancodes into unicode.
Another possible attack comes from the fact that TaintBochs never considers instruction immediates to be tainted. A guest could take advantage of this by dynamically generating code with proper immediate values that constructs a copy of a string.
Because such attacks do exist, TaintBochs can never prove the absence of errors; we don't expect to use it against actively malicious guests. Instead, TaintBochs is primarily focused on being a testing and analysis tool for finding errors.
TaintBochs supports a variety of methods for introducing taints:
Keyboard tainting simply taints bytes as they are read from the simulated keyboard controller. We use this feature, for example, to taint a user-typed password inside a web browser (see section 4.1.1 for details). This features is essentially binary: keyboard tainting is either on or off.
Tainting data at the Ethernet card is a slightly more complicated process. We do not want to simply taint entire Ethernet packets, because Ethernet headers, TCP/IP headers, and most application data are of little interest to us. To address this we provide the network card with one or more patterns before we begin a simulation. TaintBochs scans Ethernet frames for these patterns, and if it finds a match, taints the bytes that match the pattern. These taints are propagated to memory as the frame is read from the card. Although this technique can miss data that should be tainted (e.g. when a string is split between two TCP packets) it has proved sufficient for our needs so far.
Our current solution to this situation, and others like it, is to allow the application to decide what is interesting or not. Specifically, we added an instruction to our simulated IA-32 environment to allow the guest to taint data: taint eax. Using this we can modify the SSH daemon to taint the user's password as soon as it is first processed. By pushing the taint decision-making up to the application level, we can skirt the thorny issue that stopped us before by tainting the password after it has been decrypted by the SSH server. This approach has the unfortunate property of being invasive, in that it requires modification of guest code. It also fails to taint encrypted data in kernel and user buffers, but such data is less interesting because the session key is also needed to recover sensitive data.
TaintBochs must provide some mechanism for answering the key questions necessary to understand taint propagation: Who has tainted data? How did they get it? and When did that happen?. It achieves this through whole-system logging.
Whole system logging records sufficient data at simulation time to reconstitute a fairly complete image of the state of a guest at any given point in the simulation. This is achieved by recording all changes to interesting system state, e.g. memory and registers, from the system's initial startup state. By combining this information with the initial system image we can ``play'' the log forward to give us the state of the system at any point in time.
Ideally, we would like to log all changes to state, since we can then recreate a perfect image of the guest at a given instant. However, logging requires storage for the log and has runtime overhead from logging. Thus, operations which are logged are limited to those necessary to meet two requirements. First we need to be able to recreate guest memory and its associated taint status at any instruction boundary to provide a complete picture of what was tainted. Second, we would like to have enough register state available to generate a useful backtrace to allow deeper inspection of code which caused tainting.
To provide this information the log includes writes to memory, changes to memory taint state, and changes to the stack pointer register (ESP) and frame pointer register (EBP). Each log entry includes the address (EIP) of the instruction that triggered the log entry, plus the instruction count, which is the number of instructions executed by the virtual CPU since it was initialized.
To assemble a complete picture of system state TaintBochs dumps a full snapshot of system memory to disk each time logging is started or restarted. This ensures that memory contents are fully known at the log's start, allowing subsequent memory states to be reconstructed by combining the log and the initial snapshot.
Logging of this kind is expensive: at its peak, it produces about 500 MB/minute raw log data on our 2.4 GHz P4 machines, which reduces about 70% when we add gzip compression to the logging code. To further reduce log size, we made it possible for the TaintBochs user to disable logging when it is unneeded (e.g. during boot or between tests). Even with these optimizations, logging is still slow and space-consuming. We discuss these overheads further in section 6.
Taint data provided by TaintBochs is available only at the hardware level. To interpret this data in terms of higher level semantics, e.g. at a C code level, hardware level state must be considered in conjunction with additional information about software running on the machine. This task is performed by the analysis framework.
The analysis framework provides us with three major capabilities. First, it answers the question of which data is tainted by giving the file name and line number where a tainted variable is defined. Second, it provides a list of locations and times identifying the code (by file name and line number) which caused a taint to propagate. By browsing through this list the causal chain of operations that resulted in taint propagation can be unraveled. This can be walked through in a text editor in a fashion similar to a list of compiler errors. Finally, it provides the ability to inspect any program that was running in the guest at any point in time in the simulation using gdb. This allows us to answer any questions about tainting that we may not have been able to glean by reading the source code.
The first capability our analysis framework integrates is the ability to scroll back and forth to any time in the programs execution history. This allows the causal relationship between different tainted memory regions to be established, i.e. it allows us to watch taints propagate from one region of memory to the next. This capability is critical as the sources of taints become untainted over time, preventing one from understanding what path data has taken through the system simply by looking at a single point.
We have currently implemented this capability through a tool called replay which can generate a complete and accurate image of a simulated machine at any instruction boundary. It does this by starting from a snapshot and replaying the memory log. It also outputs the physical addresses of all tainted memory bytes and provides the values of EBP and ESP, exactly, and EIP, as of the last logged operation. EBP and ESP make backtraces possible and EIP is identifies the line of code that caused tainting (e.g. copied tainted data). replay is a useful primitive, but it still presents us with only raw machine state. To determine what program or what part of the kernel owns tainted data or what code caused it to be tainted we rely on another tool called x-taints.
A second capability of the analysis framework is matching raw taint data with source-level entities in user code, currently implemented through a tool called x-taints, our primary tool for interpreting tainting information. It combines information from a variety of sources to produce a file name and line number where a tainted variable was defined.
x-taints identifies static kernel data by referring to System.map, a file produced during kernel compilation that lists each kernel symbol and its address. Microsoft distributes similar symbol sets for Windows, and we are working towards integrating their use into our analysis tools as well.
x-taints identifies kernel heap allocated data using a patch we created for Linux guests that appends source file and line number information to each region allocated by the kernel dynamic memory allocator kmalloc(). To implement this we added extra bytes to the end of every allocated region to store this data. When run against a patched kernel, this allows x-taints to display such information in its analysis reports.
x-taints identifies data in user space in several steps. First, x-taints generates a table that maps physical addresses to virtual addresses for each process. We do this using a custom extension to Mission Critical's crash, software for creating and analyzing Linux kernel crash dumps. This table allows us to identify the process or processes that own the tainted data. Once x-taints establishes which process owns the data it is interested in, x-taints turns to a second custom crash extension to obtain more information. This extension extracts a core file for the process from the physical memory image on disk. x-taints applies gdb to the program's binary and the core file and obtains the name of the tainted variable.
For analysis of user-level programs to be effective, the user must have previously copied the program's binary, with debugging symbols, out of the simulated machine into a location known to x-taints. For best results the simulated machine's libraries and their debugging symbols should also be available.
The final capability that the analysis framework provides is the ability to identify which code propagated taints, e.g. if a call to memcpy copies tainted data, then its caller, along with a full backtrace, can be identified by their source file names and line numbers.
x-taints discovers this by replaying a memory log and tracking, for every byte of physical memory, the PID of the program that last modified it, the virtual address of the instruction that last modified it (EIP), and the instruction count at which it was modified.2Using this data, x-taints consults either System.map or a generated core file and reports the function, source file, and line number of the tainting code.
x-taints can also bring up gdb to allow investigation of the state of any program in the simulation at any instruction boundary. Most of the debugger's features can be used, including full backtraces, inspecting local and global variables, and so on. If the process was running at the time of the core dump, then register variables in the top stack frame will be inaccurate because only EBP and ESP are recorded in the log file. For processes that are not running, the entire register set is accurately extracted from where it is saved in the kernel stack.
 |
|
Dynamic binary translators which operate at the single process level instead of the whole system level have demonstrated significant power for doing dynamic analysis of software [8]. These systems work as assembly-to-assembly translators, dynamically instrumenting binaries as they are executed, rather than as complete simulators. For example, Valgrind [19] has been widely deployed in the Linux community and provides a wide range of functionality including memory error detection (à la Purify [15]), data race detection, cache profiling, etc. Somewhere between an full simulator and binary translator is Hobbes [7], a single process x86 interpreter that can detect memory errors and perform runtime type checking. Hobbes and Valgrind both provide frameworks for writing new dynamic analysis tools.
Dynamo [3] is an extremely fast binary translator, akin to an optimizing JIT compiler intended to be run during program deployment. It has been used to perform dynamic checks to enhance security at runtime by detecting deviations from normal execution patterns derived via static analysis. This technique has been called program shepherding [16]. It is particularly interesting in that it combines static analysis with dynamic checking.
These systems have a narrower scope than TaintBochs as they operate on a single program level, but they offer significant performance advantages. That said, binary translators that can operate at the whole system level with very high efficiency have been demonstrated in research [31] and commercial [18] settings. The techniques demonstrated in TaintBochs could certainly be applied in these settings.
The term ``tainting'' has traditionally referred to tagging data to denote that the data comes from an untrusted source. Potential vulnerabilities are then discovered by determining whether tainted data ever reaches a sensitive sink. This of course differs from our use of taint information, but the fundamental mechanism is the same. A tainted tag may be literally be a bit associated with data, as in systems like TaintBochs or Perl's tainting or may simply be an intuitive metaphor for understanding the results of a static analysis.
Perl [20] provides the most well known example of tainting. In Perl, if ``tainting'' is enabled, data read by built-in functions from potentially untrusted sources, i.e. network sockets, environment variables, etc. is tagged as tainted. Regular expression matching clears taint bits and is taken to mean that the programmer is has checked that the input is ``safe.'' Sensitive built-in functions (e.g. exec) will generate a runtime error if they receive tainted arguments.
Static taint analysis has been applied by a variety of groups with significant success. Shankar et al. [24] used their static analysis tool Percent-S to detect format string vulnerabilities based on a tainting style analysis using type qualifier inference and programmer annotations. Scrash [6], infers which data in a system is sensitive based on programmer annotations to facilitate special handling of that data to allow secure crash dumps, i.e. crash dumps which can be shipped to the application developer without revealing users sensitive data. This work is probably the most similar to ours in spirit as its focus is on making a feature with significant impact on sensitive data lifetime safe. The heart of both of these systems is the CQual [23], a powerful system for supporting user extensible type inference.
Ashcraft et al. [2] successfully applied a tainting style static analysis in the context of their meta-compilation system with extremely notable success. In the context of this work they were able to discover a large number of new bugs in the Linux and OpenBSD kernels. Their system works on a more ad-hoc basis, effectively and efficiently combining programmer written compiler extensions with statistical techniques.
Static analysis and whole system simulation both have significant strengths and can be used in a complementary fashion. Both also present a variety of practical trade-offs. Static analysis can examine all paths in a program. As it need not execute every path in the program to glean information about its properties, this allows it to avoid an exponential ``blow up'' in possible execution paths. This can be achieved through a variety of means, most commonly by making the analysis insensitive to control flow. On the other hand, simulation is basically program testing with a very good view of the action. As such, it examines only execution paths that are exercised.
Static analysis is typically performed at the source code level, thus all code is required to perform the analysis, and the analysis typically cannot span multiple programs. Further, most but not all static analysis tools require some program annotation to function. Whole system simulation can be easily used to perform analysis of properties that span the entire software stack and can be essentially language independent. Possession of source code is not even required for an analysis to include a component, although it is helpful for interpreting results.
One clear advantage of dynamic analysis in general is that it actually allows the program to be run to determine its properties. Because many program properties are formally undecidable they cannot be discovered via static analysis alone. Also, because lower level analysis works at the architectural level, it makes no assumptions about the correctness of implementations of higher level semantics. Thus, higher level bugs or misfeatures (such as a compiler optimizing away memset() as described in section 2) are not overlooked.
One direction for similar inquiries might be to examine data lifetime with a more accurate simulation, such as one that would reflect the physical characteristics of the underlying devices à la work by Gutmann [11,12].
Another area for future work is improving our simulation platform. Speed is a fundamental limitation of TaintBochs' current incarnation because of the fine-grained tainting and detailed logging that it does. TaintBochs can run as much as 2 to 10 times slower than Bochs itself. The enormity of the logging done by TaintBochs also presents a problem for our postmortem analysis tools, since it can easily take minutes or hours to replay a memory log to an interesting point in time.
We have several ideas for optimizing our system. By reducing the volume of data we log, or simply doing away with our dependency on logging altogether, we could vastly improve TaintBochs overheads. The whole-system logging technique used in ReVirt [9], for example, only had a 0-8% performance cost.
Reduced logging overhead also opens up the possibility of moving TaintBochs functionality onto faster whole-system simulation environments like those discussed in section 5. The right trade-offs could allow us to do TaintBochs-like analysis in production scenarios.
We explored how whole system simulation can provide a practical solution to the problem of understanding data lifetime in very large and complex software systems through the use of hardware level taint analysis.
We demonstrated the effectiveness of this solution by implementing a whole system simulation environment called TaintBochs and applying it to analyze sensitive data lifetime in a variety of large real world applications.
We used TaintBochs to study sensitive data lifetime in real world systems by examining password handing in Mozilla, Apache, Perl, and Emacs. We found that these systems and the components that they rely on handle data carelessly, resulting in sensitive data being propagated widely across memory with no provisions made to purge it. This is especially disturbing given the huge volume of sensitive data handled by these applications on a daily basis. We further demonstrated that a few practical changes could drastically reduce the amount of long lived sensitive data in these systems.
This work was supported in part by the National Science Foundation under Grant No. 0121481 and a Stanford Graduate Fellowship.
When allocation and zeroing does become necessary, the Linux kernel's ``buddy allocator'' for pages is biased toward returning recently freed pages. However, its actual behavior is difficult to predict, because it depends on the system's memory allocation pattern. When single free pages are coalesced into larger free blocks by the buddy allocator, they are less likely to be returned by new allocation requests for single pages. They are correspondingly more likely to be returned for multi-page allocations of the proper size, but those are far rarer than single-page allocations.
The Linux kernel ``slab'' memory allocator draws each allocation from one of several ``pools'' of fixed-size blocks. Some commonly allocated types, such as file structures, have their own dedicated pools; memory for other types is drawn from generic pools chosen based on the allocation size. Within each pool, memory is allocated in LIFO order, that is, the most recently freed block is always the first one to be reused for the next allocation.
The GNU C library, version 2.x, uses Doug Lea's implementation of malloc() [17], which also pools blocks based on size. However, its behavior is far more complex. When small blocks (less than 512 bytes each) are freed, they will be reused if allocations of identical size are requested immediately. However, any allocation of a large block (512 bytes or larger) causes freed small blocks to be coalesced into larger blocks where possible. Otherwise, allocation happens largely on a ``best fit'' basis. Ties are broken on a FIFO basis, that is, less recently freed blocks are preferred. In short, it is difficult to predict when any given free block will be reused. Dynamic data that is never freed behaves in a manner essentially equivalent to static data.
Most of the accounts above only describe when memory tends to reallocated, not when it is cleared. These are not the same because in most cases, reallocated memory is not necessarily cleared by its new owner. Memory used as an input or output buffer or as a circular queue may only be cleared as it is used and perhaps not at all (by this owner) if it is larger than necessary. Padding bytes in C structures, inserted by the programmer manually or the compiler automatically, may not be cleared either.